前言
浏览器作为前端开发工程师的主战场,每天我们都要和它打交道,因此能更好的搞懂现代高级浏览器(以Chrome为例),对前端工程师的开发和性能优化的理解,都有很大的帮助。本文在经典系列文章Inside look at modern web browser的基础上,结合我的实际经验,尽可能通俗易懂的解释现代浏览器的主要工作原理。
前置知识之CPU & GPU & Process & Thread
- 中央处理器,计算机的核心
- 能处理任何数学计算图形绘制等任何任务,只要知道怎么干
- 曾经的单核,现在的多核,计算能力更强大
博士生,能处理任何问题(简单或复杂),可人数极少

- 擅长处理简单的任务,但同时跨多个内核
- 从名字看,擅长进行图像处理
- 近年来,随着 GPU 加速计算的发展,越来越多的计算放在GPU上了
小学生,只会重复性计算(简单),但人数庞大
应用程序,是使用操作系统提供的机制在CPU和GPU上运行。
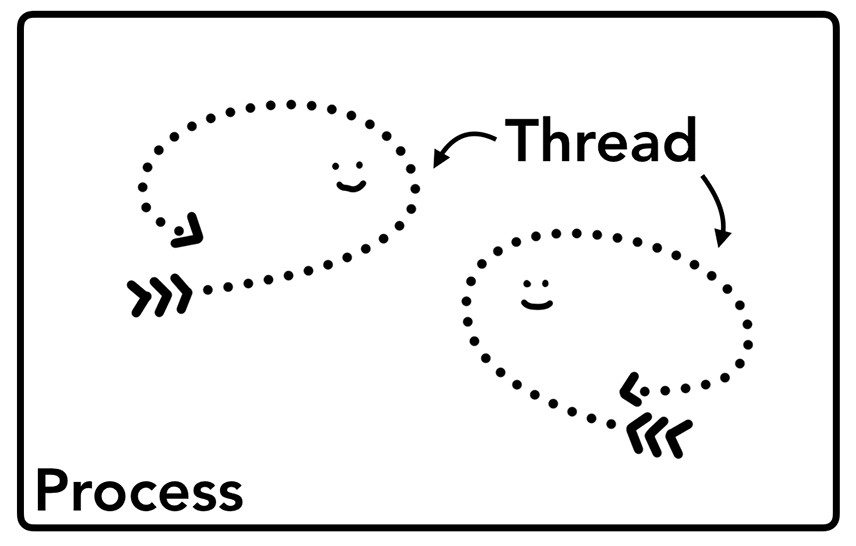
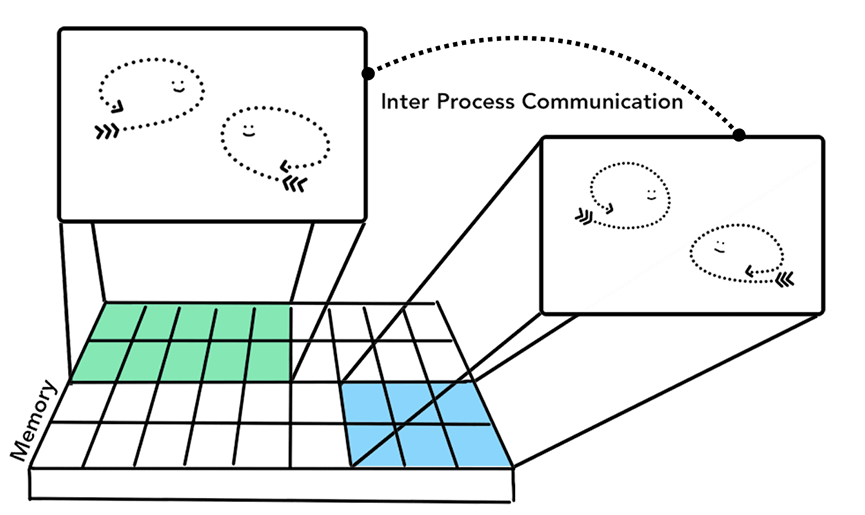
Process可以描述为运行状态中的程序。
Thread是存在于Process内部并用来执行其程序任务的某一部分。
启动程序时,将会创建一个进程。 该程序可能会创建线程来帮助它工作,但这是可选的。 操作系统为进程提供了一“块”内存,并且所有程序状态都保存在该专用内存空间中。 当你关闭程序时,该进程也会消失,操作系统会释放内存。
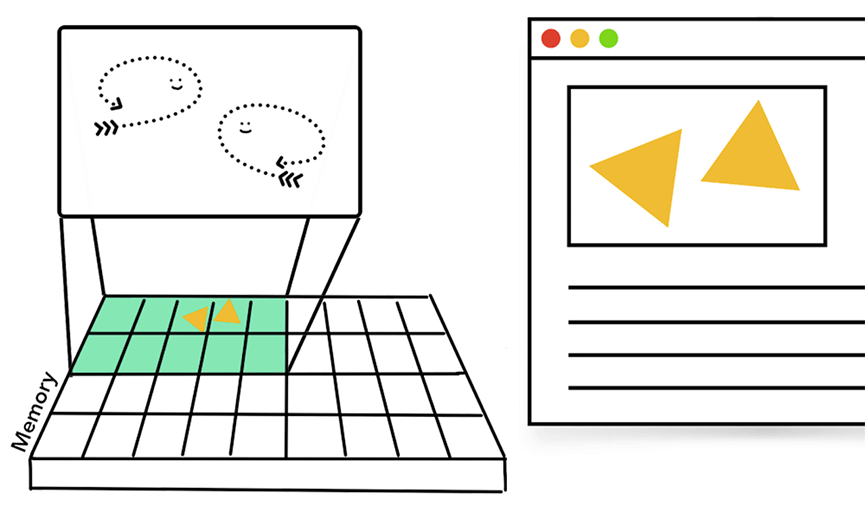
进程可以要求操作系统启动另一个进程来执行不同的任务。 当这种情况发生时,将为新进程分配不同的内存。 如果两个进程需要通信,他们可以通过使用进程间通信(IPC)来实现。 许多程序都是以这种方式工作的,因此如果一个工作进程失去响应,则可以重新启动它,而不会停止运行程序的其他进程。
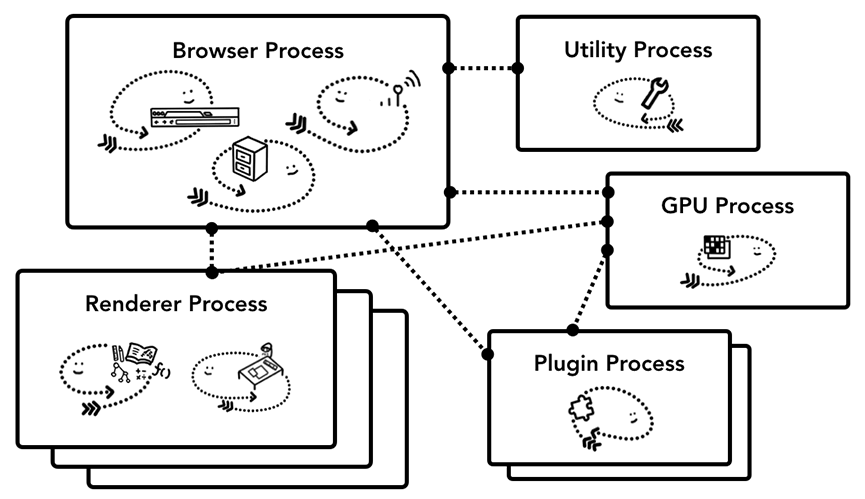
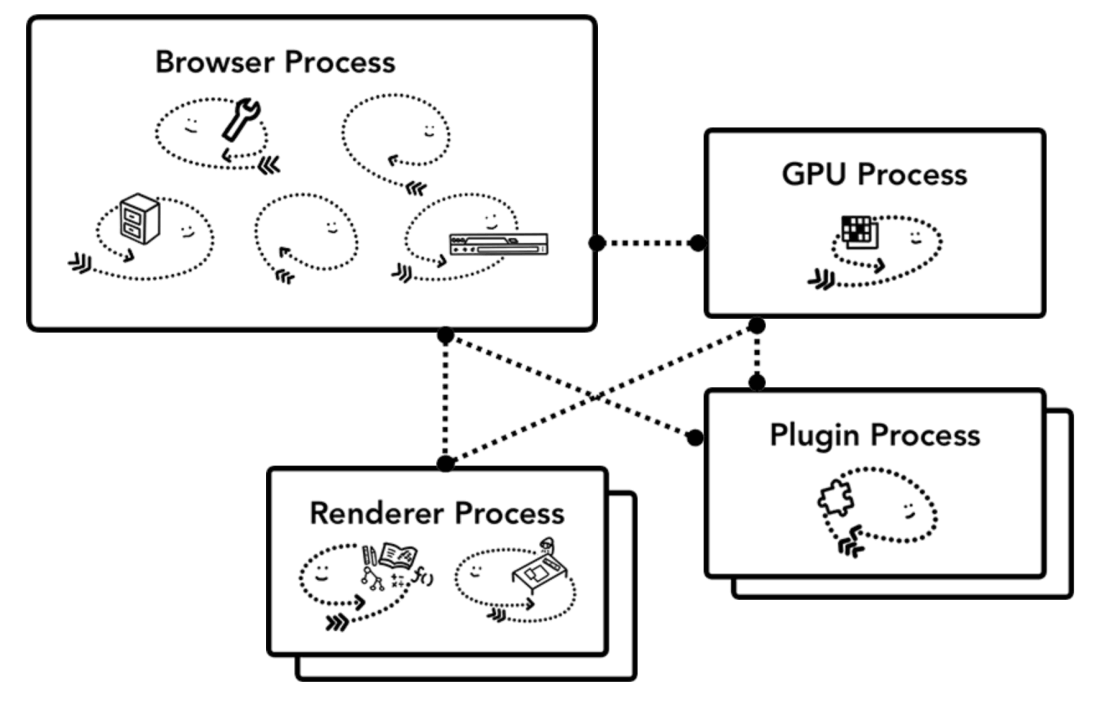
现代浏览器(Chrome)架构
我们以Chrome为例,顶部是浏览器进程与处理应用程序不同部分的其他进程协调。 对于渲染器进程,会创建多个进程并将其分配给每个选项卡。 Chrome 还为每个选项卡提供了一个进程。
| 进程名 | 进程描述 |
|---|---|
| Browser Process | 控制chrome的地址栏,书签栏等界面,也可能包括其他可见的和不可见的,比如网络请求,读取文件等 |
| Network Process | 控制对互联网上发起请求,获取数据 |
| Storage Process | 控制文件/数据的获取 |
| Renderer Process | 控制每个tab下的网页内容展示 |
| Plugin Process | 控制网站用到的插件,比如flash |
| GPU Process | 与其他进程隔离处理GPU任务。会被分成不同的进程,因为GPU要处理来自多个应用程序的请求,并最终将它们绘制在同一个屏幕上。 |
| Utility Process | 处理网络请求等 |
| Extension Process | 安装的chrome插件进程 |
更多进程可以在浏览器的“更多→更多工具→任务管理器”里观察
多进程架构的优点
- 每个tab有各自的进程,一个崩溃,其他不受影响;如果都在一个进程,一崩全崩
- 使得浏览器可以对某些特性的某些进程进行沙箱处理,比如渲染进程不能操作文件的读取
- 每个进程都有自己的私有内存空间,彼此独立,所以也通常包含了底层基础建设的副本,比如V8
开启tab都是会创建进程,也意味着增加资源(CPU,GPU,内存)的消耗,因此Chrome是有进程上限的(取决于机器的设备性能)。但当超过这个上限之后Chrome会把相同站点的tab合并到一个进程中,以节省资源。
内存小怪兽不是随便叫的,因此不要多开tab,不用的要及早关掉。
当使用Chrome的时候,其中调用的服务也是和tab管理一样,比如当机器设备性能好的时候,每个服务会以独立的进程形式存在,这样虽然消耗了更多资源,但是能提供更快和更稳定的服务。
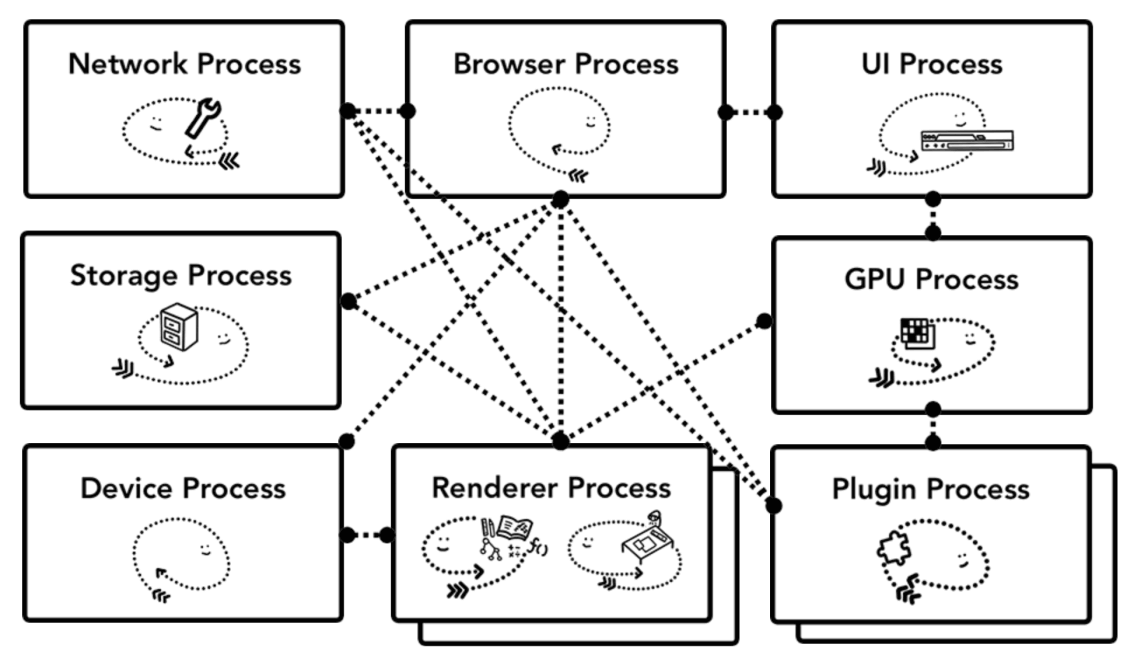
如果机器不怎么好,那就会把某些服务合并在一个进程中,以较少资源消耗。
输入URL到页面渲染结束
传统的过程
- url解析
- dns域名解析
- 查找浏览器缓存
- 查找系统缓存
- 查找路由缓存
- 家产ISP服务商的DNS缓存
- 从根域名服务器递归查询IP
- TCP链接(3次握手,TLS7次)
- 请求和传输数据
- 浏览器渲染页面
- 关闭链接
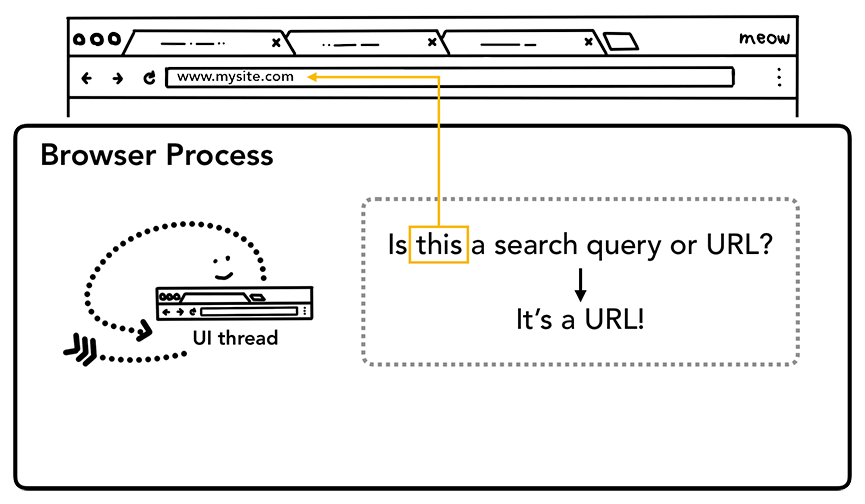
那这里重点是浏览器是怎么渲染的呢?
在地址栏输入,UI thread会判断是设置,搜索还是URL
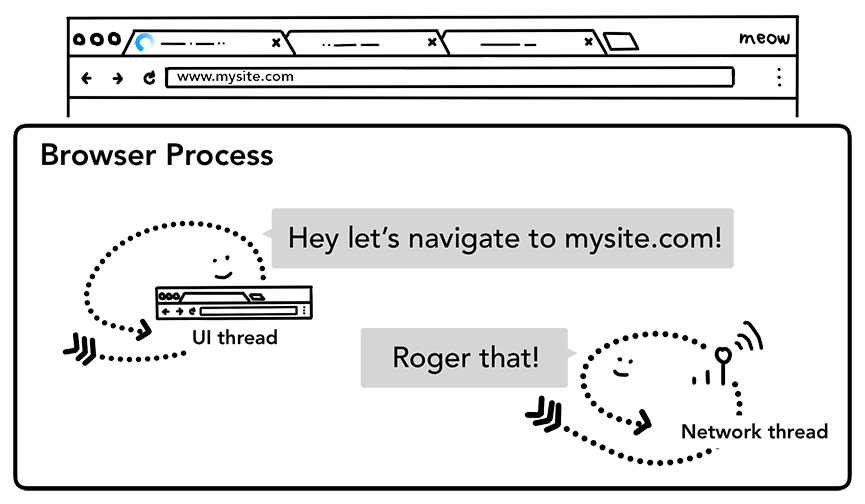
浏览器对请求站点发起网络请求,Network thread会接管请求
- Service Worker
- DNS查找
- 建立TLS(https)连接
- 对返回的response根据状态码来判断是否需要后续请求(301,302)
- response中的Content-Type标识了资源的类型
处理资源请求response
- 获取html(Content-Type: text/html;charset=utf-8)
- 如果资源有download属性,则会被放入下载管理器处理
- 恶意网站检查
- CORB检查,被标识为跨域的数据不能被chrome渲染
- 都ok后,资源将被Render Process接受并处理。


请求之前
在浏览器发起网络请求的时候,就已经同步地开启了一个Render Process(因为请求一般都有几十到几百毫秒的消耗,这样可以起到优化提速的作用)。这就意味着当请求resopnse返回数据的时候,Render Process已经就绪,万事俱备只欠东风。
如果碰到跨域就需要另外的流程处理
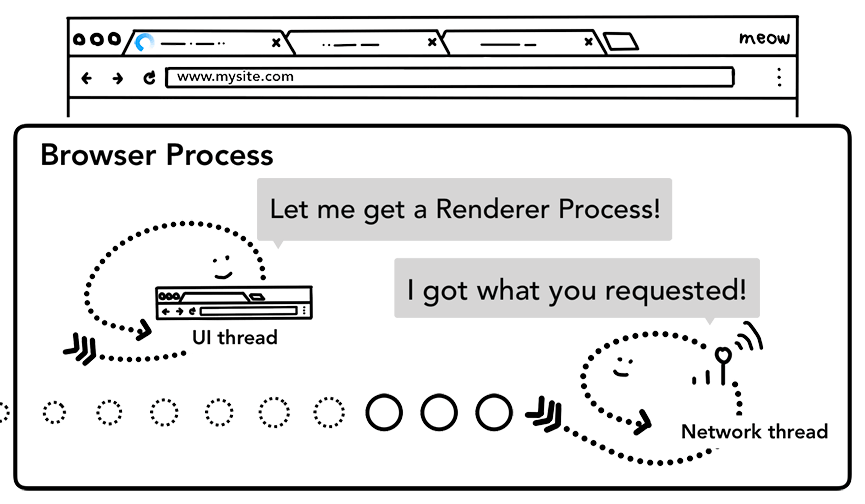
请求之后,渲染之前
- Browser Process通知Renderer Process,准备渲染
- 把html的内容一并发给Render Process
- 更新地址栏(https标识等UI设置)
- tab的history更新,前进/后退更新
- tab会被存储到disk,方便我们关了后恢复
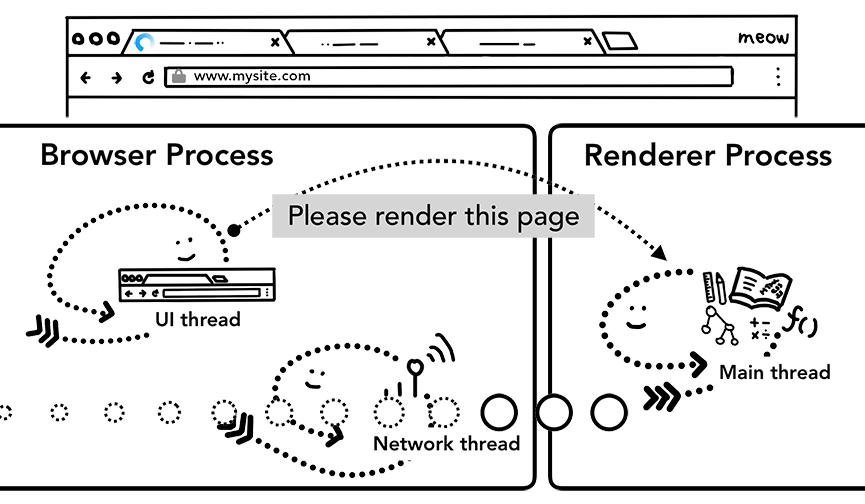
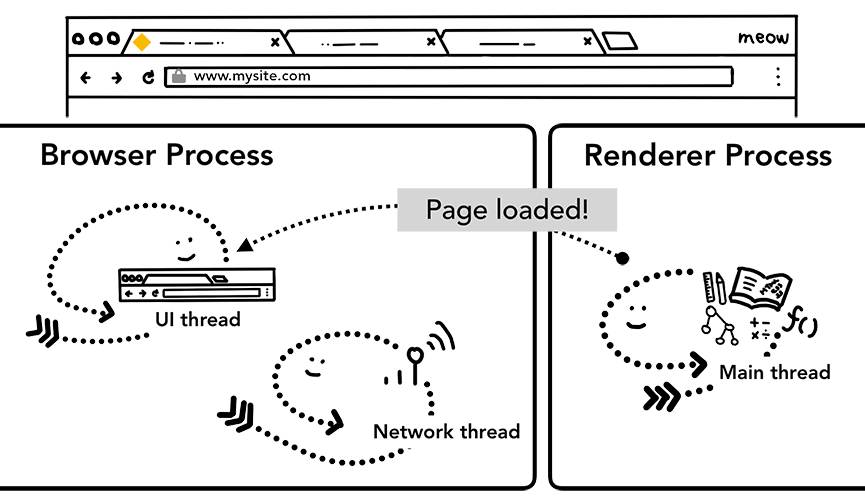
当Renderer Process结束后,同样会通知Browser Process(在页面的onload之后)。
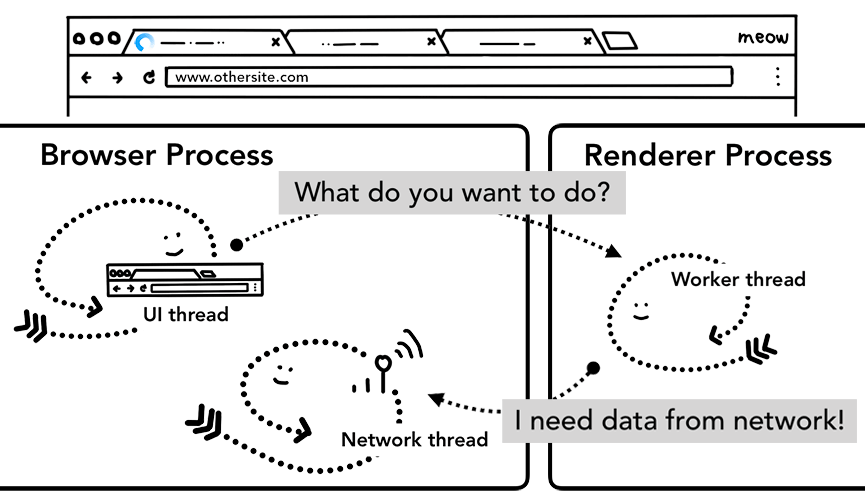
嗯?Service Worker?
- 请求代理,动态的控制从缓存取,还是拿新的
- js写的,运行在Renderer Process中(下下图)
- 当js代码中注册了Service Worker,运行后浏览器就会为其作用域(默认是和js脚本的url相对的./)作为一个引用来保存
- 当url请求发起后,Network thread会先检查url是否作用域上存在Service Worker
- 如果存在Service Worker,会启用Renderer Process来运行Service Worker中的代码
- 根据代码里的逻辑判断是从cache里获取data还是重新请求
- Preload机制(运行Service Worker后,万一还是要发起请求,时间上浪费了~平行发起请求)

先等一下,我们看下渲染流程
渲染流程,从上至下,大致分为:
- Javascript
- Style
- Layout
- Paint
- Composite
渲染之解析
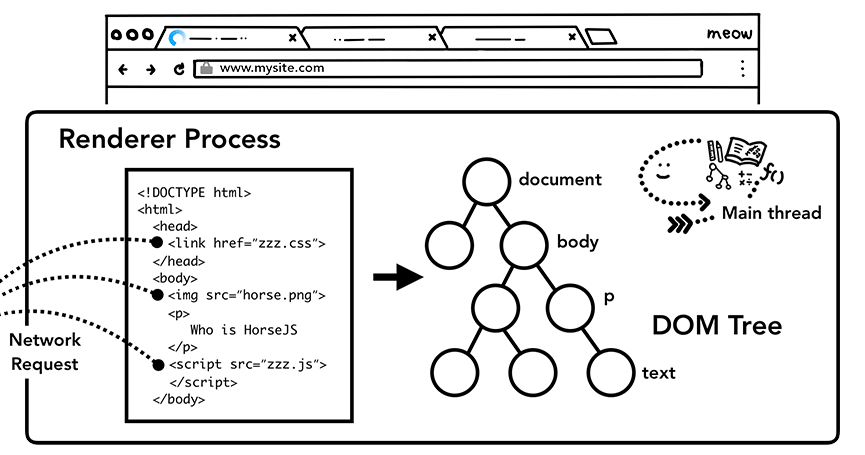
到这,Renderer Process终于可以大展身手了:
- 解析html,构建DOM
- 加载文档中img,css,js资源
- 并行的
- html解析器会对img和css生成标记,然后通知Network thread去请求,不阻塞解析
- js资源请求和运行,会阻塞解析
区别对待js的原因也很简单,因为js的运行可能改变html的结构。
对于两种标签的资源加载方式:
- script:可以灵活使用defer或async解决阻塞解析的问题
- link:preload,标识资源要尽可能快的加载,因为是必须的
渲染之style生成
在DOM生成后,接下来就该处理CSS了:
- 解析css内容,生成不同的rule
- 根据css选择器,给对应的dom元素设置相应的rule
- 选择器出现的顺序必定跟构建DOM树的顺序一致,即保证选择器在构建到当前节点时,已经可以准确判断该节点所匹配的规则,不需要后续节点信息
- css样式匹配时是从右向左匹配的,DOM找到它所有匹配的样式后再做加权计算,确定最终样式
所以同学们有没有看过Chrome工具Element,现在知道为什么css选择器是反的了吧
- 生成CSSOM:树形形式的所有CSS选择器和每个选择器的相关属性的映射,具有树的根节点,同级,后代,子级和其他关系。
浏览器有自己默认的dom元素css属性,一般我们可以用normailze.css去磨平

到此为止,有了DOM Tree和CSSOM,就可以依据两者来构建Render Tree:
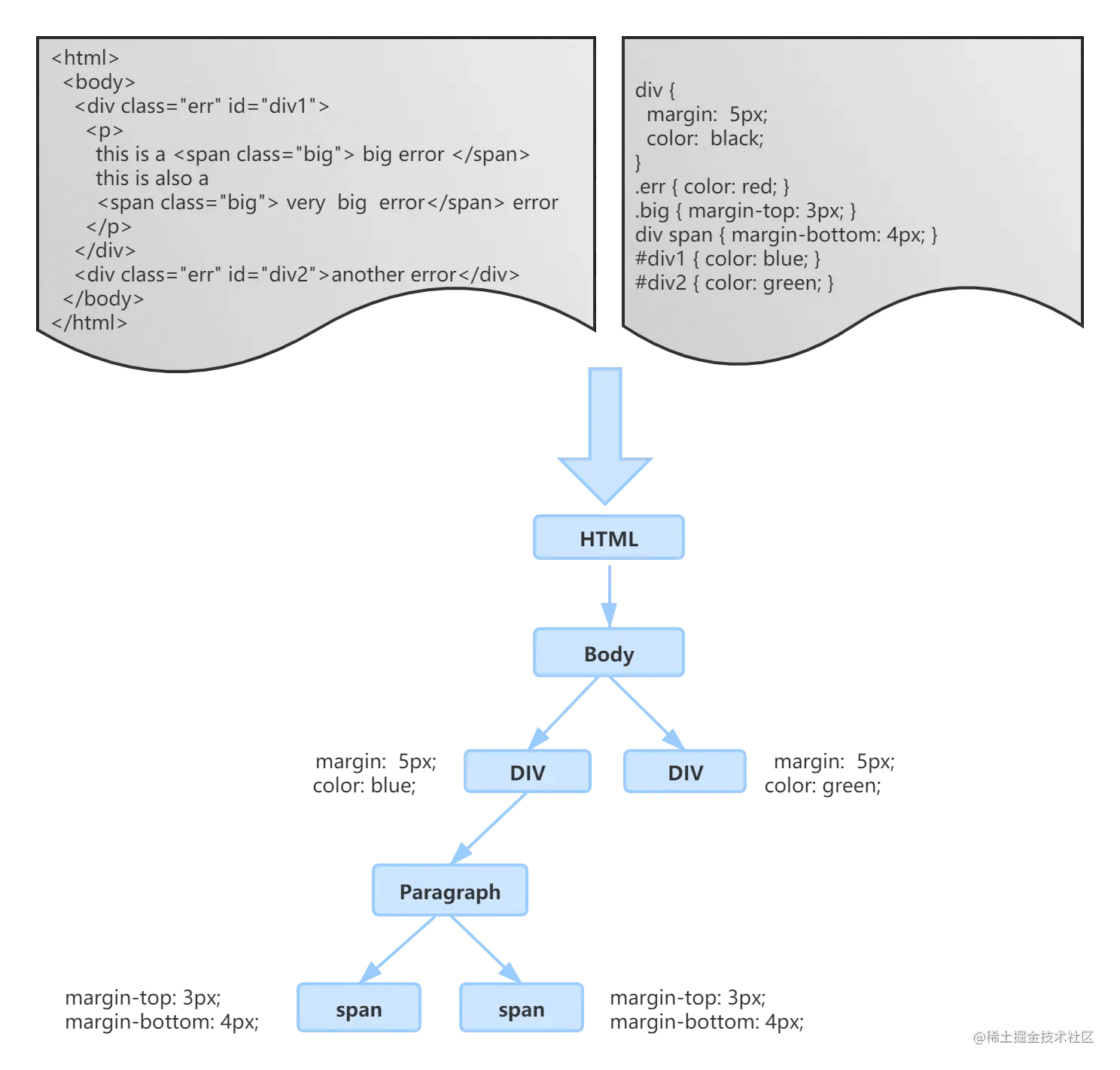
渲染之布局(Layout)
当每个DOM元素有各自的style后,就需要布局元素的位置。Renderer Process会遍历DOM元素,计算样式,并且生成布局Layout Tree。
Layout Tree:类似DOM Tree,但只是包含元素显示的必要信息,比如坐标,比如形状,又比如尺寸大小
这里需要注意,有些属性会改变layout,比如:
- display: none 不会被计算进Layout Tree
- visibility: hidden 会进Layout Tree
- 伪元素content有值 会进Layout Tree,即使不是真的元素

Layout会损耗大量的性能,也是页面渲染的瓶颈,大到页面布局,小到字体换行,都是由Layout阶段计算处理得到的。因此在后续的交互操作中,要减少对Layout的调用频率。
渲染之绘制(Paint)
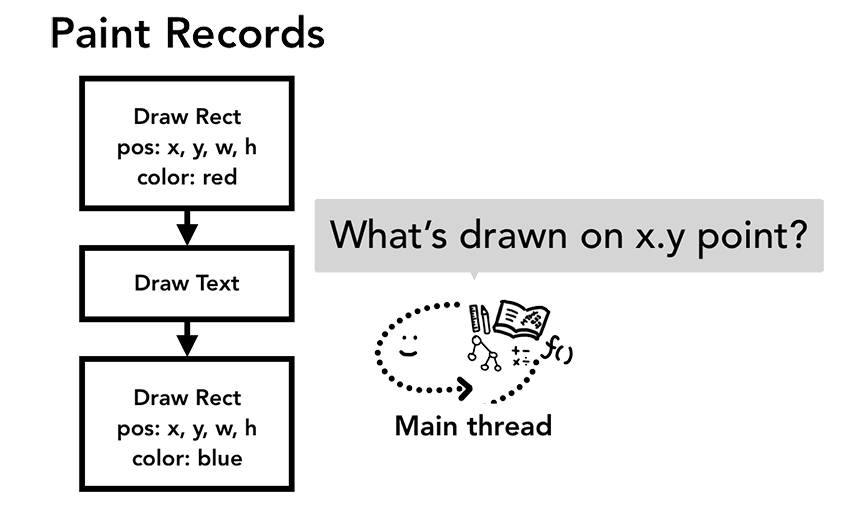
到了这步,会对上一步生成的Layout Tree进行遍历,生成一份带有DOM元素绘制内容和顺序的Paint Records。
过程和canvas绘图的思维很像,后画的会覆盖前画的
相对上一步Layout,Paint的消耗小多了。
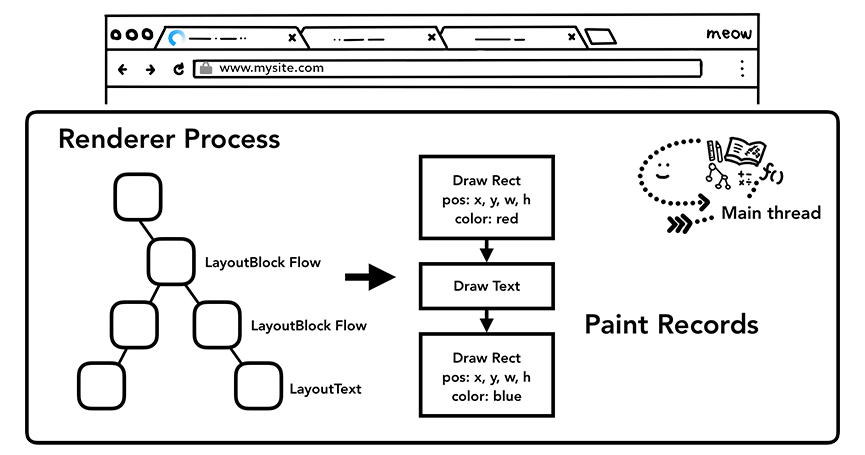
渲染之合成(Compositing)
合成是将页面的绘制部分放在一起在屏幕上显示的过程。
前面我们已经说了,Layout费尽心思给页面元素计算好了位置尺寸Layout Tree,Paint在Layout Tree成果上得到了绘制内容和顺序,那接下来就是该真的画到浏览器上了~这下该轮到Compositor thread上场了。
- 把页面分成n个独立的图层(layer),得到Layer Tree
这里就有个分层的问题,Compositor thread是如何知道分层的?- 2D transfrom
- opacity
- css fliters:常用filter和background-filter
- 3D属性:perspective或transform属性,硬件加速
- will-change
- vedio标签
- canvas标签
由此可见,我们隐藏某个元素的时候,如果可以,性能最好的是opacity,因为实在compositing阶段,或者加个will-change
坚持使用transformhe opacity来实现动画
用will-change或translateZ提升移动的元素
虽然layer的机制能很好的提升后续的渲染性能,但并不是说越多越好,因为每一图层都与需要内存和管理的开销,过多的图层栅格化也可能会影响每一帧的速度。所以css不要滥用,尤其分层的属性要慎用,动画的时候要三思。

- 对每个图层进行栅格化(rasterize)
- 对图层内容进行分割
- Raster thread对分割的内容进行栅格化
- 将结果保存到GPU内存中
- 图层栅格化可以有优先级,在视窗中的优先级最高
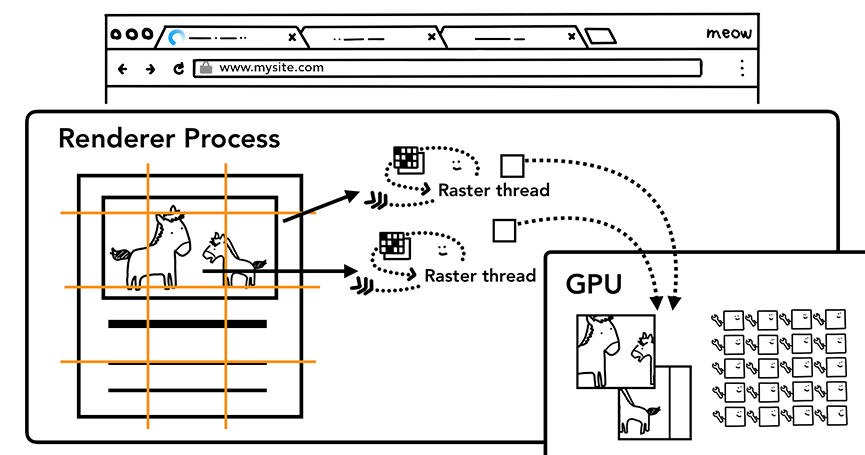
- 当图层都栅格化之后,就可以生成新的合成帧(Compositor Frame)
- 交给GPU渲染
- 如果因为操作或其他原因产生新的合成帧(Compositor Frame),一并交给GPU,一起渲染
由此,当滚动页面或元素动画的时候,由于图层已经栅格化了,所以不需要再重新计算,只需要再合成新的一帧就行了。
渲染流程中的开销
渲染的阶段,每个阶段都会用到上一个阶段生成的成果。所以在性能优化的问题上要考虑某个地方的改动处于什么阶段,因为后面的阶段也会一起变动。这也就是为什么我们要减少回流和重绘,尤其是回流的原因。
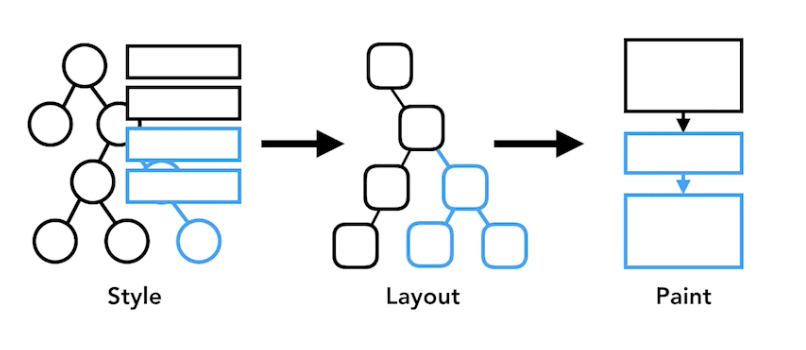
合成阶段不需要对style进行计算,也不用等待js执行,因为合成不需要渲染进程,而且有GPU缓存,所以交互的性能最好,页面动画优先用transform而不是position原因就是这个。
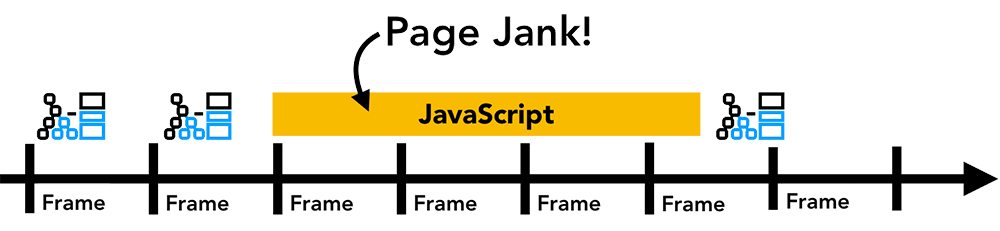

这就是js动画为什么优先用requestAnimationFrame的原因
事件交互
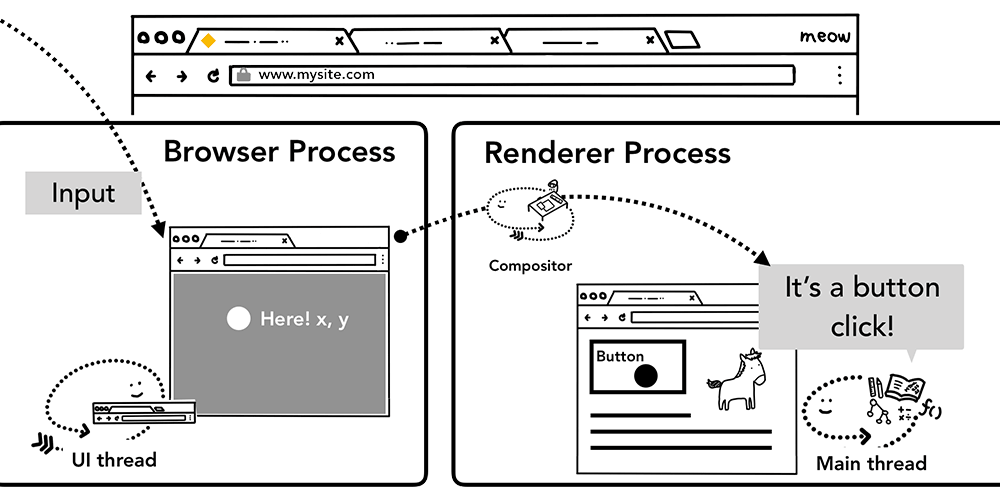
当用户在页面上进行输入交互(输入,点击,触摸等)时,其实流程是这样的:
- Browser Process知道用户触发了事件,以及触发的位置,但不知道怎么处理,因为没页面信息
- Renderer Process虽然有页面的信息,但并不知道发生了什么
- Browser Process发送事件的详细信息给Renderer Process
- Renderer Process找到相应事件对象,那么如何找到事件对象?
- Compositor thread发送事件信息给js主线程
- js主线程通过命中测试(hit test)去遍历之前生成Paint Records中的位置信息,以此确定当前点击的是哪个个对象
- 执行对象上注册的监听代码
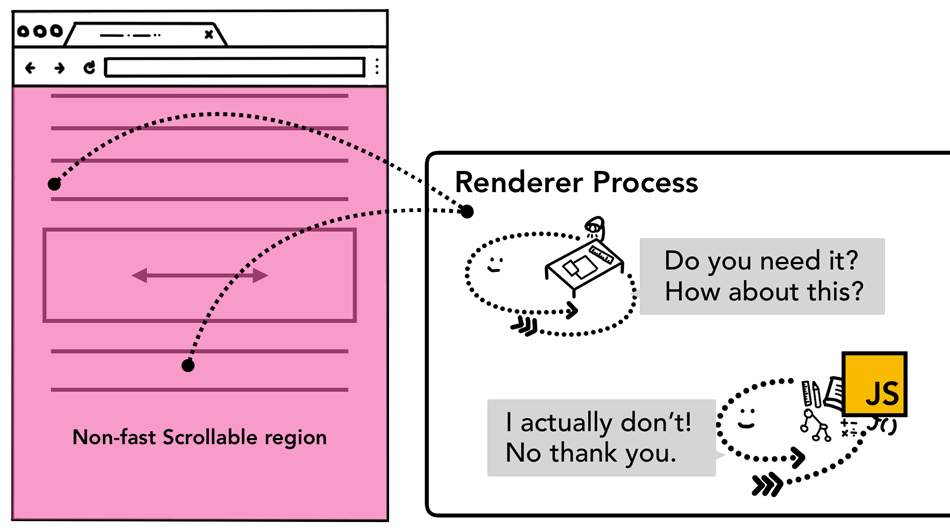
非快速滚动区域(non-fast scrollable region)
页面合成的过程中,对于有事件绑定的元素组成的区域,Compositor thread在合成的时候,会将这些区域标记为非快速滚动区域。
也就是说,对于后续滚动的操作:
- 对于非快速滚动区域,会先把事件给主线程(执行js的线程),等执行完后在做合成操作
- 对于快速滚动区域,Compositor thread就可以独立的进行合成帧(Compositor Frame)的行为,不用和主线程通信

这就是滚动事件影响性能,尽量少用的原因
其实对于事件委托,如果在可滚动的页面,其实也是会有性能影响。因为整个页面都是非滚动区域,所以你懂的。如果委托的事件逻辑庞大,那么滚动就不会顺滑,会有卡顿的感觉。
所以为了缓解这个问题(不是解决),可以在scroll监听事件的时候加上passive: true。这个属性会告诉浏览器主线程还是要执行js的,但是Compositor thread仍然可以独立去进行合成帧(Compositor Frame)。
滚动事件中性能的优化点
向主线程尽可能少的发送事件
当屏幕的fps在60的时候(低于30就会有人眼可见的卡顿了),用户就能有平滑的感觉。但通过上述事件交互的流程,对于有些输入事件,其频率会远超每秒60次(触摸屏更多),所以实际上输入事件的触发频率其实是远远高于屏幕的刷新率的。

为了尽可能少的向主线程发送事件,Chrome会连续事件(wheel,mosewheel,mousemove,pointermove,touchmove等)做一个合并,并将调度延迟到下一个requestAnimationFrame前。
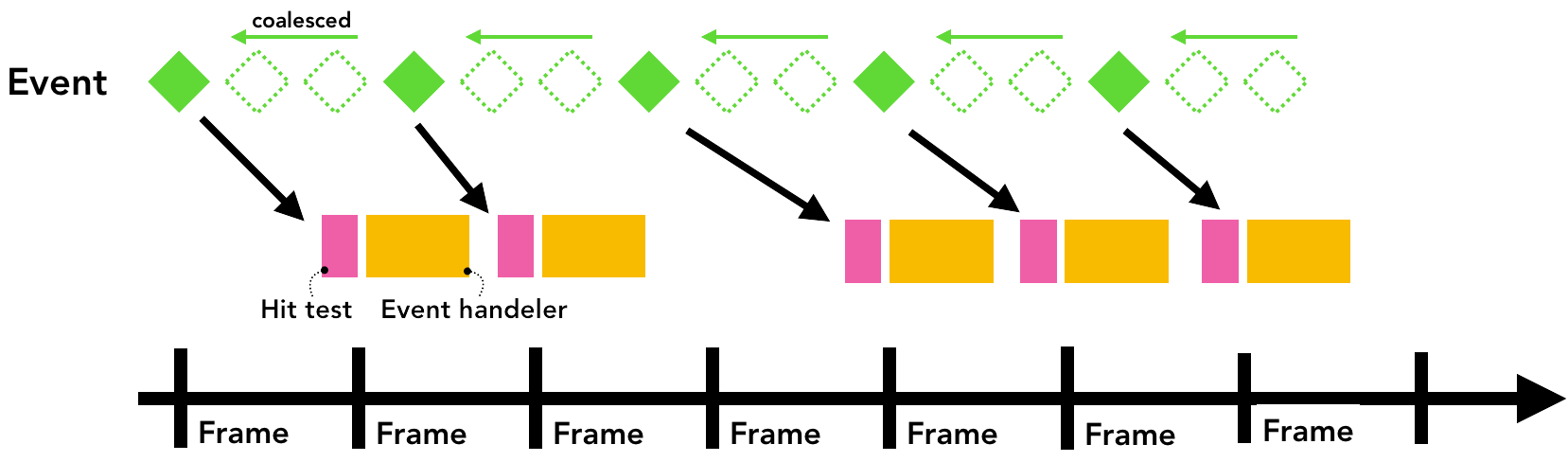
相对的,对于不频繁发生的事件(keydown,keyup,mouseup,mousedown,toushstart,touchend等)则还是会立即通信给主线程。
之前提过,浏览器很聪明,不会立马执行完就去刷新屏幕,在这里就是一个体现。
整个过程有点类似react的批量操作。
当事件需要使用连续的参数时
对于大部分应用,浏览器的事件合并机制,已经能优化绝大部分场景。
但有些特殊的,比如用鼠标或触摸去画图(有些刮刮卡应用),合并后的事件就会使页面线条不够连续。
这个时候对于鼠标事件,可以用getCoalescedEvent来获取被合成的事件的详细信息。
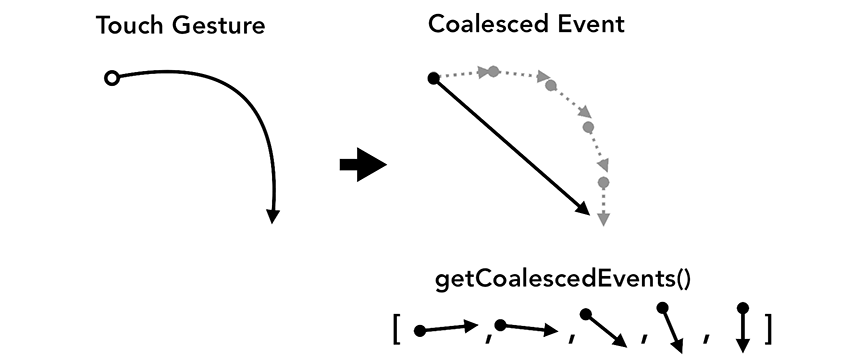
补充一下,如果是touch的事件,则需要区分其中三个比较关键的参数:
- touches:当前屏幕上所有触摸点的list
- targetTouches:绑定事件的结点的触摸点的list
- changedTouches:触发事件时发生改变的触摸点list
所以想一下,如果我们touchmove的时候写签名,应该调用event的哪个属性?


